OpenCL简介
OpenCL简介
什么是 OpenCL
OpenCL全称Open Computing Language即开放计算语言。OpenCL为异构平台提供了一个编写程序,尤其是并行程序的开放的框架标准。OpenCL所支持的异构平台可由多核CPU、GPU或其他类型的处理器组成。OpenCL由两部分组成,一是用于编写内核程序(在OpenCL设备上运行的代码) 的语言,二是定义并控制平台的API。OpenCL提供了基于任务和基于数据两种并行计算机制,它极大地扩展了GPU 的应用范围,使之不再局限于图形领域。
OpenCL由Khronos Group维护。Khronos Group是一个非盈利性技术组织,维护着多个开放的工业标准,例如OpenGL和OpenAL。这两个标准分别用于三维图形和计算机音频方面。
OpenCL源程序既可以在多核CPU上也可以在GPU 上编译执行,这大大提高了代码的性能和可移植性。OpenCL标准由相应的标准委员会制订,委员会的成员来自业界各个重要厂商。作为用户和程序员期待已久的东西,OpenCL带来两个重要变化:一个跨厂商的非专有软件解决方案;一个跨平台的异构框架以同时发挥系统中所有计算单元的能力。
OpenCL 发展历史
OpenCL最初苹果公司开发,拥有其商标权,并在与AMD,IBM,英特尔和nVIDIA技术团队的合作之下初步完善。随后,苹果将这一草案提交至Khronos Group。
2008年6月的WWDC大会上,苹果提出了OpenCL规范,旨在提供一个通用的开放API,在此基础上开发GPU通用计算软件。随后,Khronos Group宣布成立GPU通用计算开放行业标准工作组,以苹果的提案为基础创立OpenCL行业规范。5个月后的2008年11月18日,该工作组完成了OpenCL 1.0规范的技术细节。2010年6月14日,OpenCL 1.1 发布。2011年11月15日,OpenCL 1.2 发布。2013年11月19日,OpenCL 2.0发布。2015年3月3日,OpenCL 2.1发布。2016年4月18日,OpenCL 2.2发布,这是目前 OpenCL 的最新版本。
OpenCL 的优点
利用 OpenCL 可以充分利用设备的并行特性
现代处理器的架构已经将并行计算作为了提高性能的一个最重要途径。高性能 CPU的由于很难克服提高时钟频率后的散热问题转而使用增加运算核心的方法加速。作为图形渲染专用的处理器,GPU具有高度的并行特性。由于相关应用的需要,GPU也从单一的图形渲染设备转化为作为通用计算的协处理器。相对于 CPU,GPU有很多自己独有的特点。
- GPU的运算核心数量要远远超过高端 CPU的核心数量。GPU的每个运算核心并没有 CPU的运算核心工作频率高,但是其总体性能-芯片面积比和性能-功耗比都很高,在处理并行计算的相关任务中有很大优势。
- GPU是通过大量并行线程之间交织运行隐藏全局访问的延迟,同时GPU还拥有大量的寄存器、局部存储器及Cache等来提升外部存储的访问性能。
除了以上两点,GPU相对于 CPU还有很多其他特性。这些特性决定了GPU的计算模式是以一种并行的方式进行计算的。基于 GPU或者其他并行运算设备的算法与传统的基于CPU的串行算法有很大差别:
- 并行算法中要有大量的线程在运行,而一般的串行算法都只有一个线程在运行。
- 并行算法中的每个线程的行为需要尽量保持一致,如果分支很多,各线程又选择不同路径执行,会严重降低 GPU运算的效率。在CPU中,即使有两个线程的行为高度不一致,也不会非常影响性能。
- 在程序不加特殊约束的情况下,并行运算设备是不保证每个线程看到的全局内存是一致的。程序员有责任维护线程同步以及内存管理等任务。
- 在传统的串行运算设备中,例如 CPU,线程之间切换的开销是比较大的。所以一般来说,是不鼓励程序员为一个算法开启大量线程的。而在类似于 GPU的并行运算设备中,线程之间的切换是非常廉价的。这些设备也正是通过线程之间切换来隐藏一些内存访问延迟的。与CPU相反,并行设备一般是不鼓励设备运行具有很少线程的算法。
OpenCL 为程序员提供了控制并行计算设备的一些接口以及一些控制运算单元行为的类 C 编程语言。用户可以利用 OpenCL 接口开发并行度很高的程序,并且将其运行在GPU或者其他处理设备上。
OpenCL 为程序员提供了平台独立性
如今大部分的高端的计算机系统基本上都引入了高性能的 CPU,GPU和其它类型的处理器。这就为软件开发提出一个内在的要求,即必须保证编写的软件能够在各种异质平台上自由移植,并且能充分而合理的利用到整个计算机系统的所有计算资源。
OpenCL正是为了满足用户的这个要求而设计的。它应用范围广泛,从嵌入式消费类软件的开发到高性能计算解决方案,都可以通过其完成。OpenCL具有一个底层程序接口,和一个高性能,可移植的抽象层,它为并行计算提供了一个有效的开发环境,一个平台独立的工具和丰富的中间软件层。
通过传统的方法开发一个运行在异质平台,例如包括多核 CPU和GPU的平台,并行运算程序是十分困难的。传统的基于多核 CPU架构的并行计算程序会假设地址空间在计算过程中是始终共享的,GPU并行计算模型则有着非常复杂的内存层次和矢量操作,并且不同平台,不同厂商,不同产品型号的GPU往往有着不同的架构。这些限制使得软件开发人员很难开发出一款能高效的运用各种异质平台计算资源的软件。
OpenCL标准的诞生为软件开发人员能够高效利用各种异构处理平台提供了充分保障。从高性能计算服务器,到家用计算机系统,再到手持设备,从高端 GPU,高端多核 CPU到DSP,和 Cell/B.E. processor。OpenCL支持各种各样的并行处理器的组合平台。
OpenCL 框架
平台模型
平台模型如图1所示。由一个主机 (host)连接一个或多个 OpenCL设备构成。其中每个 OpenCL 设备又可以分割成一个或多个计算单元 (CU),每个计算单元又可以进一步分割成一个或多个处理单元 (PE),各种计算操作都是在处理单元中完成的。所有由 OpenCL编写的应用程序都是从 host启动并在 host上结束的,host端管理着整个平台上的所有计算资源。应用程序会从host端向各个 OpenCL设备的处理单元发送计算命令。在一个计算单元内的所有处理单元会执行完全相同的一套指令流程。指 令流可以是 SIMD模式或者SPMD模式。

内存模型
OpenCL 将内核程序中用到的内存分为了四类不同的类型:
- 全局内存 (global memory): 工作空间内所有的工作节点都可以读写此类内存中的任意元素。OpenCL C提供了缓存global buffer的内建函数。
- 常量内存 (constant memory): 工作空间内所有的工作节点可以只读此类内存中的任意元素。 host负责分配和初始化 constant buffer,在内核执行过程中保持不变。
- 局部内存 (local memory): 从属于一个工作组的内存,同一个工作组中所有的工作节点都可以共享使用该类内存。其实现既可以为 OpenCL 执行为其分配一块专有内存空间,也有可能直接将其映射到一块 global buffer 上。
- 私有内存 (private memory): 只从属于当前的工作节点。一个工作节点内部的 private buffer 其他节点是完全不可见的。
下表描述了 host 和 kernel 是如何管理和使用各类内存的:
| 全局 | 常量 | 本地 | 私有 | ||
|---|---|---|---|---|---|
| Host 端 | 分配 | 动态 | 动态 | 动态 | 不可分配 |
| Host 端 | 访问 | 可读写 | 可读写 | 不可访问 | 不可访问 |
| Kernel 端 | 分配 | 不可访问 | 静态 | 静态 | 静态 |
| Kernel 端 | 访问 | 可读写 | 只读 | 可读写 | 可读写 |
图2描述了各类内存区域的作用空间即其在平台中的位置。
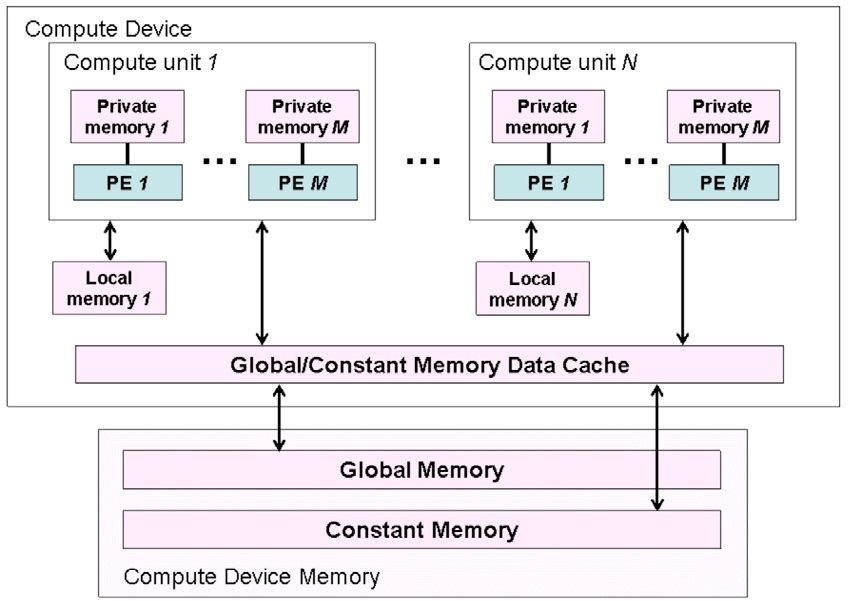
OpenCL规定了一个较为宽松的内存模型,它不保证 kernel内每个工作节点所看到的所有内存状态和其他工作节点所看到的是一致的。它只规定在一个工作节点内部访问内存必须是一致的,在一个工作组内的所有工作节点在执行了工作组内存屏障函数后相应的 local buffer和global buffer必须是一致的。OpenCL不保证不同工作组之间的工作节点访问内存的一致性。
执行模型
OpenCL的执行模型可以分为两部分,一部分是在 host上执行的主程序(host program),另一部分是在 OpenCL设备上执行的内核程序(kernels),OpenCL通过主程序来定义上下文并管理内核程序在OpenCL设备的执行。
OpenCL执行模型的核心工作就是管理 kernel在OpenCL设备上的运行。在 Host创建一个 kernel 程序之前必须先为该 kernel创建一个标识了索引的工作空间,kernel会在工作空间每个节点 (work item)上执行。该工作空间可以是一维,二维或者三维的。每个工作节点相应维度上的索引都被定义为节点在该维度上的全局 ID(global ID)。所有工作节点都将执行相同的 kernel程序,但是由于路径不同 计算出来的数据可以是不同的。OpenCL在了对工作空间提供了全局索引之外也提供了较小粒度的工作组(work group)空间。工作组的维度必须和整个工作空间的维度相同,并且整个工作空间在每个维度上都必须能等分成若干个工作区间。每个工作组在都有一个唯一的工作组 ID(work group ID),工作组内部的节点相对该工作组的位置索引被称作局部ID(local ID)。
OpenCL规范中使用 NDRang来定义 N-维索引空间。它由一个长度为N的整数数组构成( N为1,2或3,对应一维二维或三维空间)该数组中的元素指定了工作空间每个维度的上工作节点的个数。工作节点的 global ID和local ID以及工作组ID都是N维,每个维度都是从0开始依次加1。
编程模型
OpenCL支持按数据并行的编程模型和按任务并行的编程模型,同时也支持由这两种混合而成的混合编程模型。其中按数据并行的模型在编 写OpenCL并行程序中最为经典。
数据并行模型是指同一系的列指令会作用在内存对象的不同元素上,即在不同内存元素上按这个指令序列定义了统一的运算。用户可以利用工作节点的 global ID或local ID来映射该工作节点所作用的内存元素。在一个严格意义上的数据并行的编程模型中,每个工作节点和该节点上 kernel程序所作用的内存之间都有着一对一的映射关系。OpenCL实现的是一个宽松的数据并行模型,并不要求一定要有严格的一对一映射。OpenCL提供了一种分级数据并行编程模型。其分级方式有两种方法,显示分级模型要求用户不仅要规定用于进行数据并行计算的所有工作节点的数目,同时也必须规定每个节点所属的工作组。而隐式分级模型则将后者交由OpenCL实现来管理。
在任务并行编程模型是指工作空间内的每个工作节点在执行 kernel程序时相对于其他节点是绝对独立的。在这种模式下对每个工作节点都相当于工作在一个单一的计算单元内,该单元内只有单一工作组,该工作组中只有该节点本身在执行。
OpenCL 编程一般步骤
下面通过一个简单的例子来说明 OpenCL 编程的一般步骤。
平台初始化
include 头文件
使用 OpenCL API 编程与一般 C/C++ 引入第三方库编程没什么区别。所以,首先要做的自然是 include 相关的头文件。
#if defined(__APPLE__) || defined(__MACOSX)
#include <OpenCL/cl.hpp>
#else
#include <CL/cl.h>
#endif
查询并选择一个 platform
首先我们要取得系统中所有的 OpenCL platform。所谓的 platform 指的就是硬件厂商提供的 OpenCL 框架,不同的 CPU/GPU 开发商(比如 Intel、AMD、Nvdia)可以在一个系统上分别定义自己的 OpenCL 框架。所以我们需要查询系统中可用的 OpenCL 框架,即 platform。使用 API 函数 clGetPlatformIDs 获取可用 platform 的数量:
cl_int status = 0;
cl_uint numPlatforms;
cl_platform_id platform = NULL;
status = clGetPlatformIDs( 0, NULL, &numPlatforms);
if(status != CL_SUCCESS){
printf("Error: Getting Platforms\n");
return EXIT_FAILURE;
}
然后根据数量来分配内存,并得到所有可用的 platform,所使用的 API 还是 clGetPlatformIDs。在 OpenCL 中,类似这样的函数调用很常见:第一次调用以取得数目,便于分配足够的内存;然后调用第二次以获取真正的信息。
if (numPlatforms > 0) {
cl_platform_id *platforms = (cl_platform_id *)malloc(numPlatforms * sizeof(cl_platform_id));
status = clGetPlatformIDs(numPlatforms, platforms, NULL);
if (status != CL_SUCCESS) {
printf("Error: Getting Platform Ids.(clGetPlatformIDs)\n");
return -1;
}
现在,所有的 platform 都存在了变量 platforms 变量中,接下来需要做的就是取得我们所需的 platform。我的PC上配置的是 Intel 处理器和 AMD 显卡。通过使用 clGetPlatformInfo 来获得 platform 的信息。通过这个 API 可以知晓 platform 的厂商信息,以便我们选出需要的 platform。代码如下:
for (unsigned int i = 0; i < numPlatforms; ++i) {
char pbuff[100];
status = clGetPlatformInfo(
platforms[i],
CL_PLATFORM_VENDOR,
sizeof(pbuff),
pbuff,
NULL);
platform = platforms[i];
if (!strcmp(pbuff, "Advanced Micro Devices, Inc.")) {
break;
}
}
在 platform 上建立 context
首先通过 platform 得到相应的 context properties:
// 如果我们能找到相应平台,就使用它,否则返回NULL
cl_context_properties cps[3] = {
CL_CONTEXT_PLATFORM,
(cl_context_properties)platform,
0
};
cl_context_properties *cprops = (NULL == platform) ? NULL : cps;
然后通过 clCreateContextFromType 函数创建 context:
// 生成 context
cl_context context = clCreateContextFromType(
cprops,
CL_DEVICE_TYPE_GPU,
NULL,
NULL,
&status);
if (status != CL_SUCCESS) {
printf("Error: Creating Context.(clCreateContexFromType)\n");
return EXIT_FAILURE;
}
/*
函数的第二个参数可以设定 context 关联的设备类型。本例使用的是 GPU 作为OpenCL计算设备。目前可以使用的类别包括:
- CL_DEVICE_TYPE_CPU
- CL_DEVICE_TYPE_GPU
- CL_DEVICE_TYPE_ACCELERATOR
- CL_DEVICE_TYPE_DEFAULT
- CL_DEVICE_TYPE_ALL
*/
在 context 上查询 device
status = clGetContextInfo(context,
CL_CONTEXT_DEVICES,
0,
NULL,
&deviceListSize);
if (status != CL_SUCCESS) {
printf("Error: Getting Context Info device list size, clGetContextInfo)\n");
return EXIT_FAILURE;
}
cl_device_id *devices = (cl_device_id *)malloc(deviceListSize);
if (devices == 0) {
printf("Error: No devices found.\n");
return EXIT_FAILURE;
}
status = clGetContextInfo(context,
CL_CONTEXT_DEVICES,
deviceListSize,
devices,
NULL);
if (status != CL_SUCCESS) {
printf("Error: Getting Context Info (device list, clGetContextInfo)\n");
return EXIT_FAILURE;
}
与获取 platform 类似,我们调用两次 clGetContextInfo 来完成查询。第一次调用获取关联 context 的 device 个数,并根据个数申请内存;第二次调用获取所有 device 实例。如果你想了解每个 device 的具体信息,可以调用 clGetDeviceInfo 函数来获取,返回的信息有设备类型、生产商以及设备对某些扩展功能的支持与否等等。
运行时模块
前面的代码是配置好了 OpenCL 运行环境。真正的逻辑代码,即程序的任务就是运行时模块。本例的任务是在一个 4×4的二维空间上,按一定的规则给每个元素赋值,具体代码如下:
#define KERNEL(...)#__VA_ARGS__
const char *kernelSourceCode = KERNEL(
__kernel void hellocl(__global uint *buffer)
{
size_t gidx = get_global_id(0);
size_t gidy = get_global_id(1);
size_t lidx = get_local_id(0);
buffer[gidx + 4 * gidy] = (1 << gidx) | (0x10 << gidy);
}
这一段就是我们真正的逻辑,也就是代码要干的事。使用的是 OpenCL 自定的一门类C语言。
加载 OpenCL 内核程序并创建一个 program 对象
接下来要做的就是读入 OpenCL kernel 程序并创建一个 program 对象。
size_t sourceSize[] = {strlen(kernelSourceCode)};
cl_program program = clCreateProgramWithSource(context,
1,
&kernelSourceCode,
sourceSize,
&status);
if (status != CL_SUCCESS) {
printf("Error: Loading Binary into cl_program (clCreateProgramWithBinary)\n");
return EXIT_FAILURE;
}
本例中的 kernel 程序是作为静态字符串读入的(单独的文本文件也一样),所以使用的是 clCreateProgramWithSource,如果不想让 kernel 程序让其他人看见,可以先生成二进制文件,再通过 clCreateProgramWithBinary 函数动态读入二进制文件,可以保护源代码。
为指定的 device 编译 program 中的 kernel
kernel 程序读入完毕,要做的自然是使用 clBuildProgram 编译 kernel:
status = clBuildProgram(program, 1, devices, NULL, NULL, NULL);
if (status != CL_SUCCESS) {
printf("Error: Building Program (clBuildingProgram)\n");
return EXIT_FAILURE;
}
最终,kernel 将被相应 device 上的 OpenCL 编译器编译成可执行的机器码。
创建指定名字的 kernel 对象
成功编译后,可以通过 clCreateKernel 来创建一个 kernel 对象:
cl_kernel kernel = clCreateKernel(program, "hellocl", &status);
if (status != CL_SUCCESS) {
printf("Error: Creating Kernel from program.(clCreateKernel)\n");
return EXIT_FAILURE;
}
引号中的 hellocl 就是 kernel 对象所关联的 kernel 函数的函数名。要注意的是,每个 kernel 对象必须关联且只能关联一个包含于相应 program 对象内的 kernel 程序。实际上,用户可以在 cl 源代码中写任意多个 kernel 程序,但在执行某个 kernel 程序之前必须先建立单独的 kernel 对象,即多次调用 clCreateKernel 函数。
为 kernel 创建内存对象
OpenCL 内存对象是指在 host 中创建,用于 kernel 程序的内存类型。按维度可以分为两类,一类是 buffer,一类是 image。buffer 是一维的,image 可以是二维、三维的 texture、frame-buffer 或 image。本例仅仅使用 buffer,可以通过 clCreateBuffer 函数来创建。
cl_mem outputBuffer = clCreateBuffer(
context,
CL_MEM_ALLOC_HOST_PTR,
4 * 4 * 4,
NULL,
&status);
if (status != CL_SUCCESS) {
printf("Error: Create Buffer, outputBuffer. (clCreateBuffer)\n");
return EXIT_FAILURE;
}
为 kernel 设置参数
使用 clSetKernelArg 函数为 kernel 设置参数。传递的参数既可以是常数,变量,也可以是内存对象。本例传递的就是内存对象。
status = clSetKernelArg(kernel, 0, sizeof(cl_mem), (void *)&outputBuffer);
if (status != CL_SUCCESS) {
printf("Error: Setting kernel argument. (clSetKernelArg)\n");
return EXIT_FAILURE;
}
该函数每次只能设置一个参数,如有多个参数,需多次调用。而且 kernel 程序中所有的参数都必须被设置,否则在启动 kernel 程序是会报错。指定位置的参数的类型最好和对应 kernel 函数内参数类型一致,以免产生各种未知的错误。在设置好指定参数后,每次运行该 kernel 程序都会使用设置值,直到用户使用次 API 重新设置参数。
在指定的 device 上创建 command queue
command queue 用于光里将要执行的各种命令。可以通过 clCreateCommandQueue 函数创建。其中的 device 必须为 context 的关联设备,所有该 command queue 中的命令都会在这个指定的 device 上运行。
cl_command_queue commandQueue = clCreateCommandQueue(context,
devices[0],
0,
&status);
if (status != CL_SUCCESS) {
printf("Error: Create Command Queue. (clCreateCommandQueue)\n");
return EXIT_FAILURE;
}
将要执行的 kernel 放入 command queue
创建好 command queue 后,用户可以创建相应的命令并放入 command queue 中执行。OpenCL 提供了三种方案来创建 kernel 执行命令。最常用的即为本例所示的运行在指定工作空间上的 kernel 程序,使用了 clEnqueueNDRangeKernel 函数。
size_t globalThreads[] = {4, 4};
size_t localThreads[] = {2, 2};
status = clEnqueueNDRangeKernel(commandQueue, kernel,
2, NULL, globalThreads,
localThreads, 0,
NULL, NULL);
if (status != CL_SUCCESS) {
printf("Error: Enqueueing kernel\n");
return EXIT_FAILURE;
}
最后可以用 clFinish 函数来确认一个 command queue 中所有的命令都执行完毕。函数会在 command queue 中所有 kernel 执行完毕后返回。
// 确认 command queue 中所有命令都执行完毕
status = clFinish(commandQueue);
if (status != CL_SUCCESS) {
printf("Error: Finish command queue\n");
return EXIT_FAILURE;
}
将结果读回 host
计算完毕,将结果读回 host 端。使用 clEnqueueReadBuffer 函数将 OpenCL buffer 对象中的内容读取到 host 可以访问的内存空间。
// 将内存对象中的结果读回Host
status = clEnqueueReadBuffer(commandQueue,
outputBuffer, CL_TRUE, 0,
4 * 4 * 4, outbuffer, 0, NULL, NULL);
if (status != CL_SUCCESS) {
printf("Error: Read buffer queue\n");
return EXIT_FAILURE;
}
资源回收
程序的最后是对所有创建的对象进行释放回收,与C/C++的内存回收同理。
// 资源回收
status = clReleaseKernel(kernel);
status = clReleaseProgram(program);
status = clReleaseMemObject(outputBuffer);
status = clReleaseCommandQueue(commandQueue);
status = clReleaseContext(context);
free(devices);
delete outbuffer;
总结
我在这里用这个小例子说明了OpenCL的一般步骤。其实这些步骤一般都是固定的。真正需要我们注意的是 OpenCL Kernel 程序的编写。